Ant
Isaac-Ant-v0
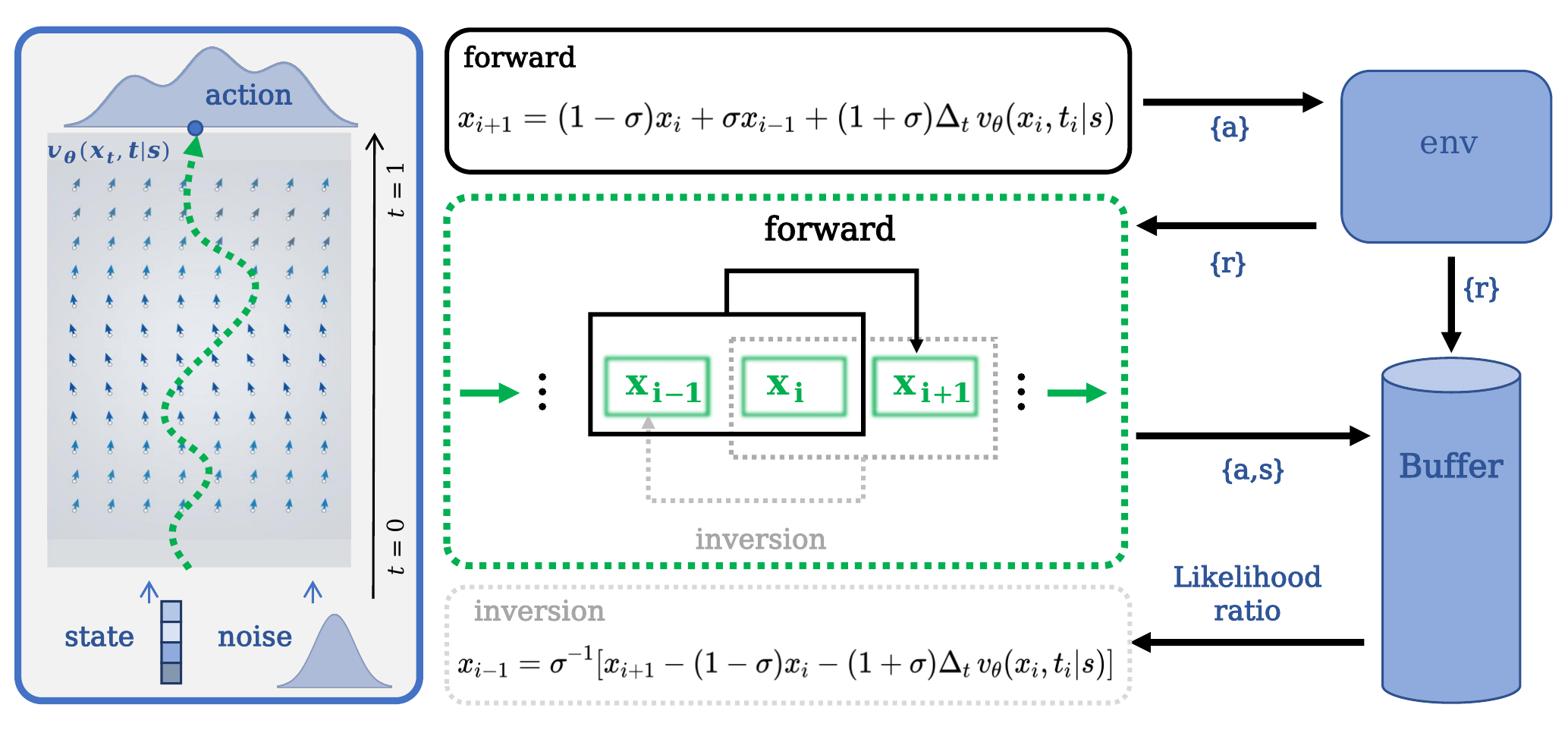
Generative policies provide expressive and multimodal action distributions, making them attractive for reinforcement learning (RL) in complex continuous-control tasks. Among them, flow-based policies are especially appealing because they generate actions through deterministic transport maps. However, applying such generative policies to likelihood-based on-policy learning remains limited by the difficulty of evaluating the probability of executed actions. Existing flow RL methods either replace the true action-density ratio with approximate surrogates, which can introduce biased updates, or recover exact likelihoods through dummy-action augmentation, which enlarges the policy space and increases computation. In this work, we propose GenPO++, a reversible generative policy optimization framework that uses history states as auxiliary memory in a high-order reversible ODE solver, yielding exact inversion without changing the original action dimension. The resulting generative policy map has a log-determinant determined only by fixed solver coefficients, enabling exact and Jacobian-free likelihood-ratio computation. This design preserves the expressiveness of generative flow policies while avoiding both action ratio bias and dummy-action overhead. We evaluate GenPO++ on large-scale simulated control, fine-tuning, and real-world robotic manipulation tasks, where it achieves competitive or superior performance over state-of-the-art on-policy RL methods, while improving training stability and computational efficiency.
Videos are ordered as in the experiments: IsaacLab benchmarks, RoboMimic fine-tuning tasks, then real-world hand manipulation.
Eight simulated control tasks covering locomotion, manipulation, and whole-body control.
Pretrained flow-matching manipulation policies fine-tuned online.
Single-arm object manipulation.
Dual-arm object rearrangement.
Long-horizon precision insertion.
RobotEra XHand nut-bolt manipulation across different object geometries.
Real-world deployment.
Real-world deployment.
Real-world deployment.